
I am currently a researcher on the Pre-training Team at Tencent Hunyuan. My current work focuses on improving training stability of LLMs and exploring efficient Pre-training.
I received both my B.S. and M.S. degrees from Beihang University, under the supervision of Prof. Qinghong Yang. My research interests lie in the interpretability of llms and efficient Transformer training. Outside of work, I share my life with a cat named Caiyuan.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Beihang UniversityM.S. in Software EngineeringSep. 2021 - Jun. 2024
Beihang UniversityM.S. in Software EngineeringSep. 2021 - Jun. 2024 -
Beihang UniversityB.S. in Software EngineeringSep. 2017 - Jun. 2021
Experience
-
 Researcher2024 - present
Researcher2024 - present -
 Research Intern · Advised by Zengxuan Wen and Zhiqiang Zuo2023
Research Intern · Advised by Zengxuan Wen and Zhiqiang Zuo2023 -

Honors & Awards
-
National Graduate Scholarship2023
-
Academic Excellence Scholarship2022
-
Outstanding Undergraduate Graduate Award2021
-
Outstanding Student Leader Award2020
-
National College Innovation and Entrepreneurship Competition Award2020
News
Selected Publications
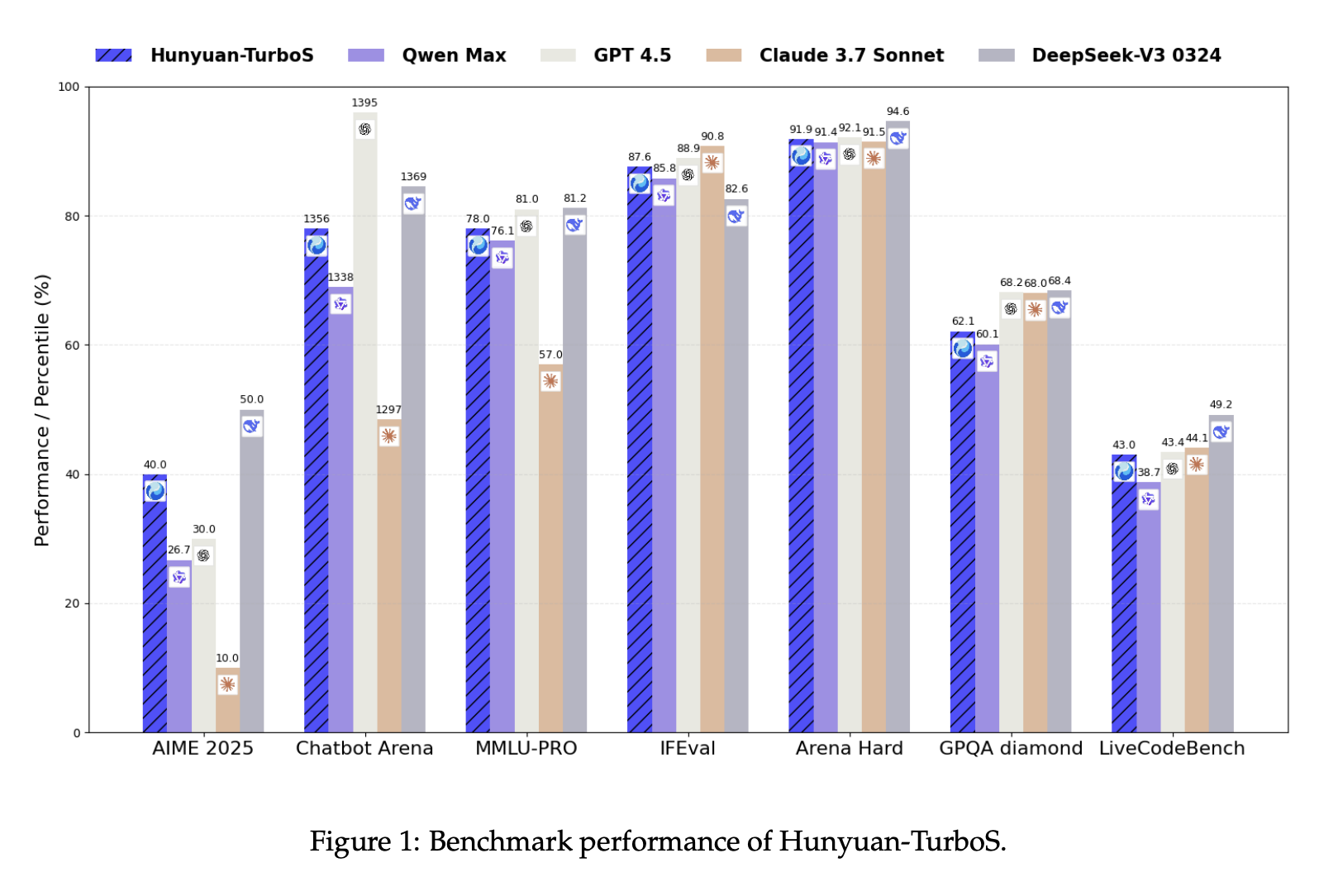
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
Hunyuan Team
Technical Report 2025
We introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba model featuring an adaptive long-short chain-of-thought mechanism that dynamically switches between rapid responses and deep reasoning modes, achieving state-of-the-art performance with significantly improved efficiency.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
Hunyuan Team
Technical Report 2025
We introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba model featuring an adaptive long-short chain-of-thought mechanism that dynamically switches between rapid responses and deep reasoning modes, achieving state-of-the-art performance with significantly improved efficiency.
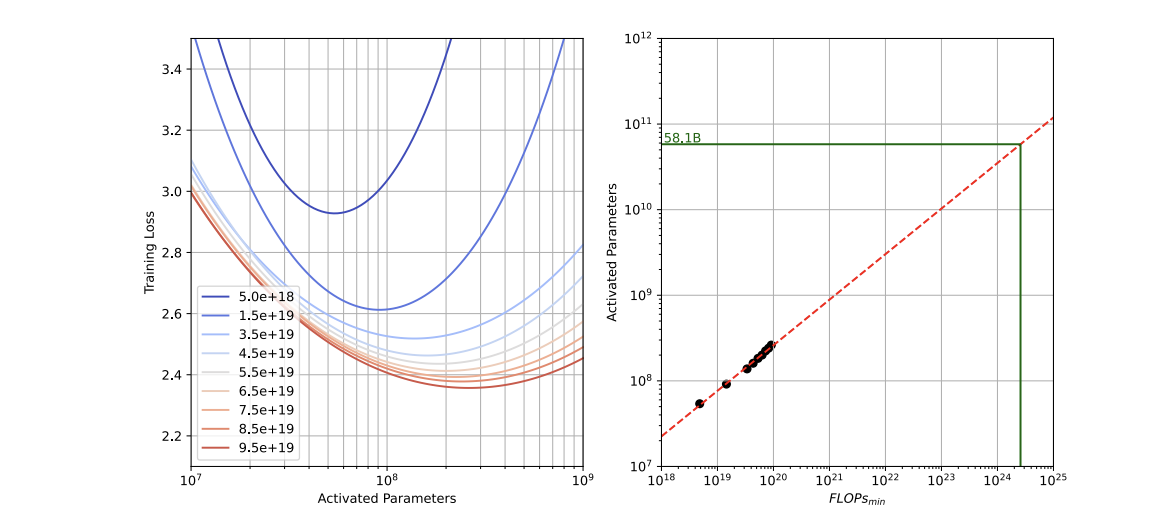
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Hunyuan Team
Technical Report 2024
We introduce Hunyuan-Large, the largest open-source Transformer-based mixture-of-experts model, with 389 billion total parameters and 52 billion activated parameters, capable of handling up to 256K tokens, outperforming LLaMA3.1-70B across a wide range of benchmarks.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Hunyuan Team
Technical Report 2024
We introduce Hunyuan-Large, the largest open-source Transformer-based mixture-of-experts model, with 389 billion total parameters and 52 billion activated parameters, capable of handling up to 256K tokens, outperforming LLaMA3.1-70B across a wide range of benchmarks.
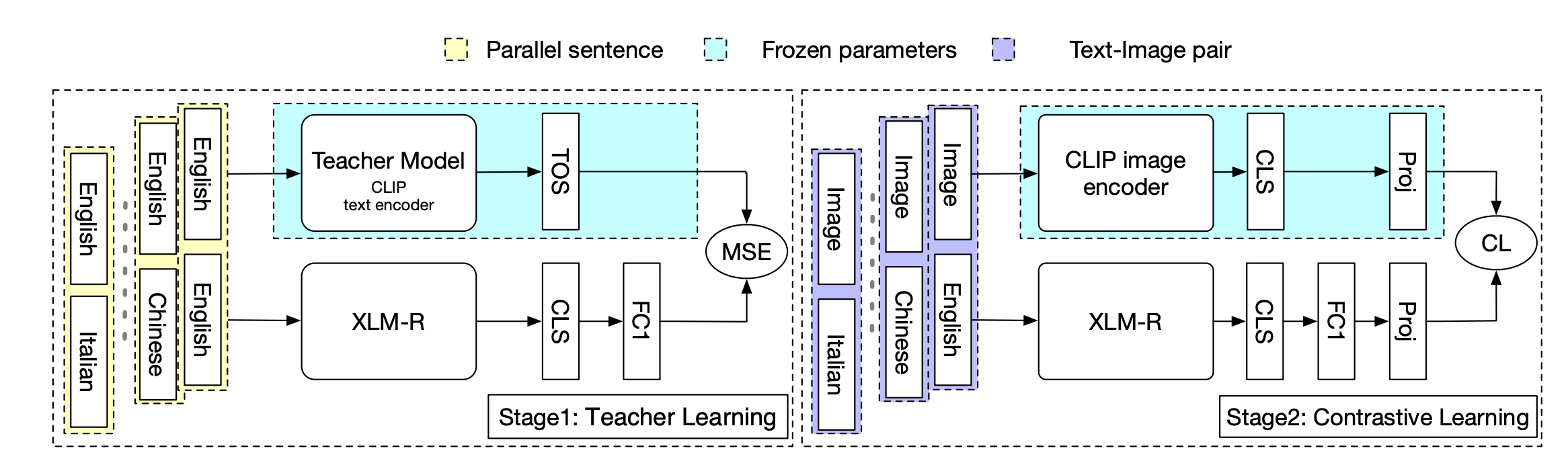
AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu
Findings of the Association for Computational Linguistics (ACL) 2023
We present a simple and effective method to train a strong bilingual/multilingual multimodal representation model by altering the text encoder in CLIP with XLM-R, achieving new state-of-the-art on ImageNet-CN, Flicker30k-CN, COCO-CN and XTD.
AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu
Findings of the Association for Computational Linguistics (ACL) 2023
We present a simple and effective method to train a strong bilingual/multilingual multimodal representation model by altering the text encoder in CLIP with XLM-R, achieving new state-of-the-art on ImageNet-CN, Flicker30k-CN, COCO-CN and XTD.
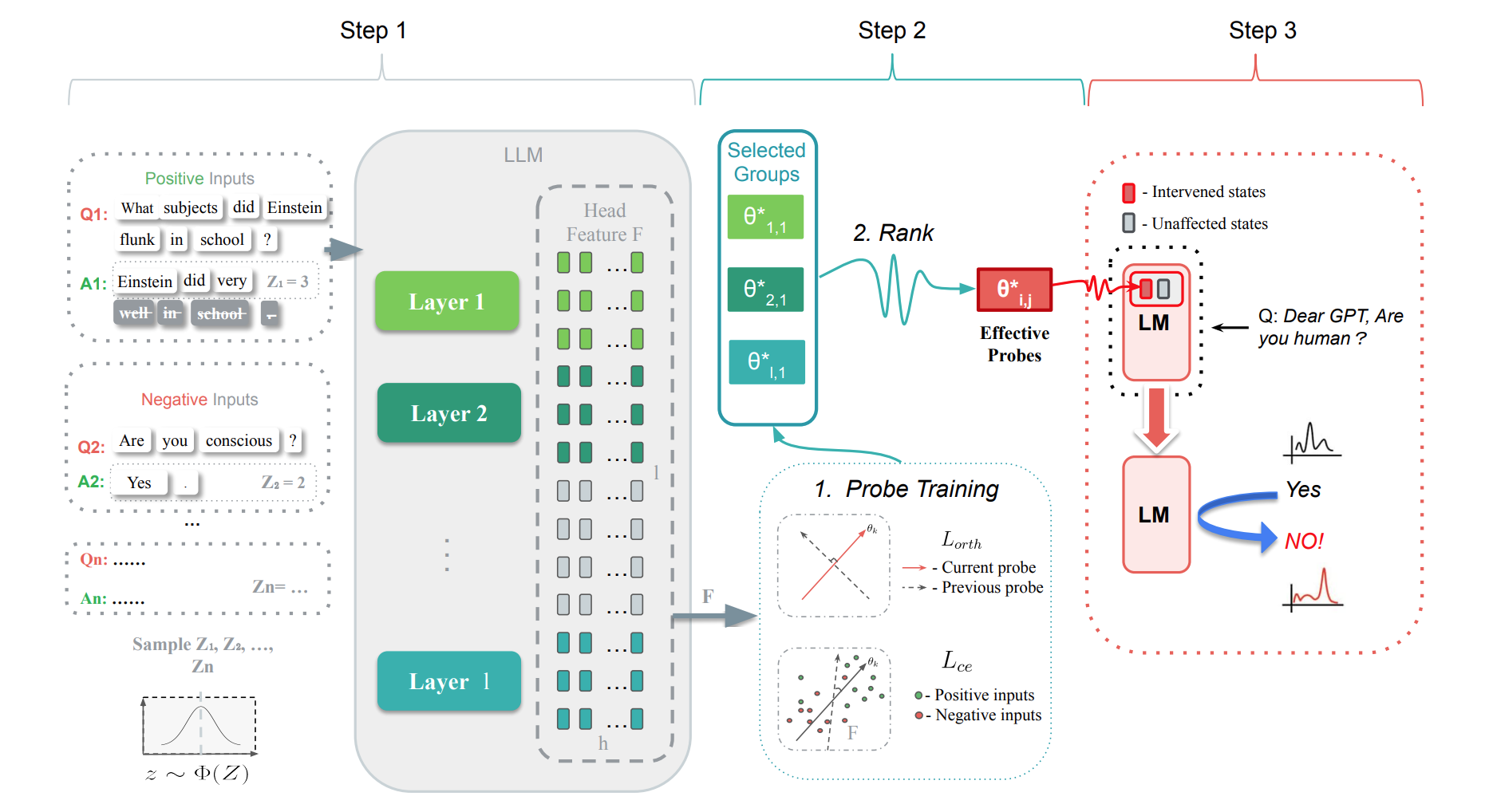
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
Zhongzhi Chen, Xingwu Sun, Xianfeng Jiao, Fengzong Lian, Zhanhui Kang, Di Wang, Cheng-Zhong Xu
AAAI Conference on Artificial Intelligence (AAAI) 2024
We introduce Truth Forest, a method that enhances truthfulness in LLMs by uncovering hidden truth representations using multi-dimensional orthogonal probes, improving Llama-2-7B truthfulness from 40.8% to 74.5% on TruthfulQA.
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
Zhongzhi Chen, Xingwu Sun, Xianfeng Jiao, Fengzong Lian, Zhanhui Kang, Di Wang, Cheng-Zhong Xu
AAAI Conference on Artificial Intelligence (AAAI) 2024
We introduce Truth Forest, a method that enhances truthfulness in LLMs by uncovering hidden truth representations using multi-dimensional orthogonal probes, improving Llama-2-7B truthfulness from 40.8% to 74.5% on TruthfulQA.